
Embedding models convert text into vectors, and cosine similarity between those vectors tells you how related two texts are. But what does a score of 0.4 actually mean? Is that good? How much does a paragraph score against its own article? What about an irrelevant question - where does it land?
I wanted to build intuition for these numbers, so I measured them.
The Experiment
I took the Wikipedia article on fly fishing and measured cosine similarity between the full article and chunks of different sizes - random paragraphs, sentences, and individual words from it. I also compared the article against relevant questions, irrelevant questions, and random English words. I ran this on two embedding models: OpenAI text-embedding-3-large and Amazon Titan Embeddings v2.
Chunk Size vs. Similarity
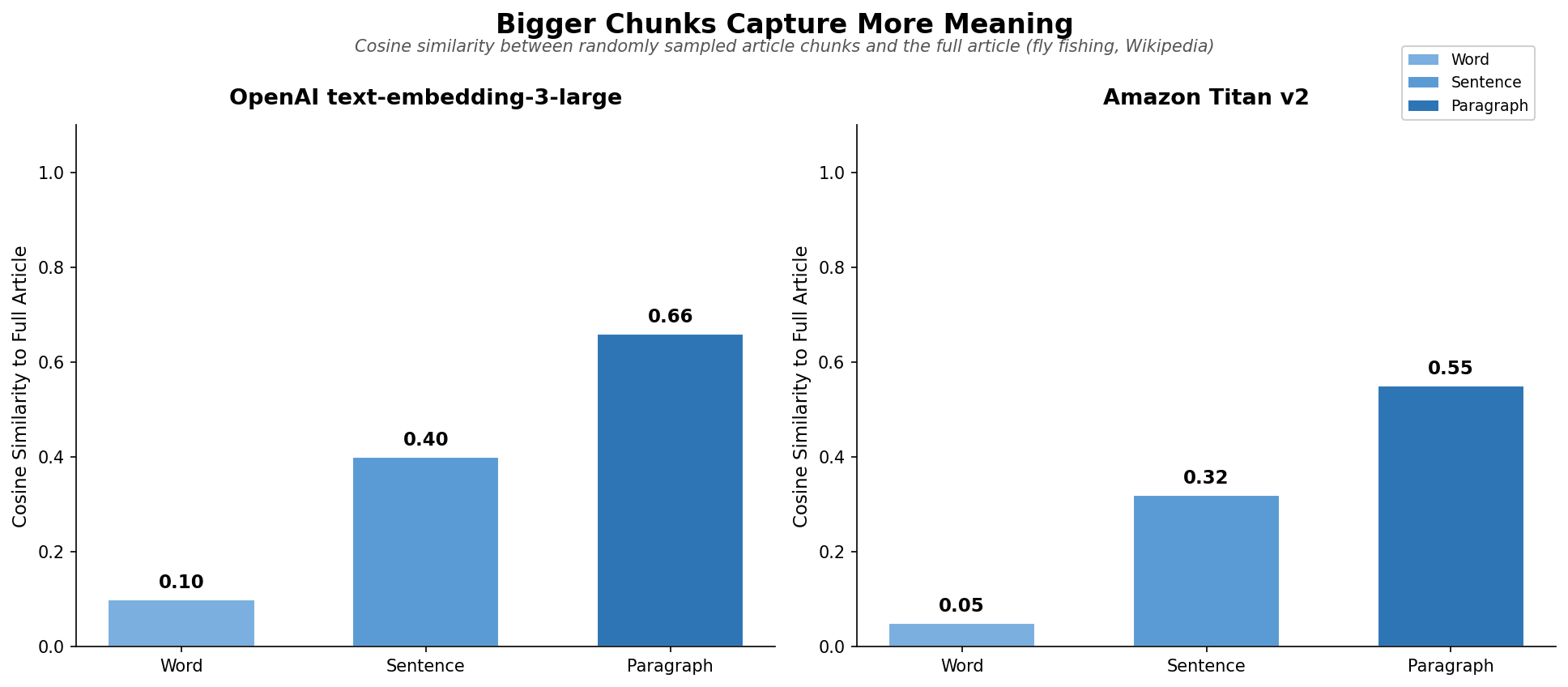
No surprises in the ranking - bigger chunks score higher:
| Chunk type | OpenAI | Titan |
|---|---|---|
| Word from article | 0.10 | 0.05 |
| Sentence from article | 0.40 | 0.32 |
| Paragraph from article | 0.66 | 0.55 |
What’s worth noting is the magnitude. A paragraph captures only about two-thirds of the article’s semantic signal. A sentence - about a third. A single word - practically nothing.
Where Queries Land on That Scale
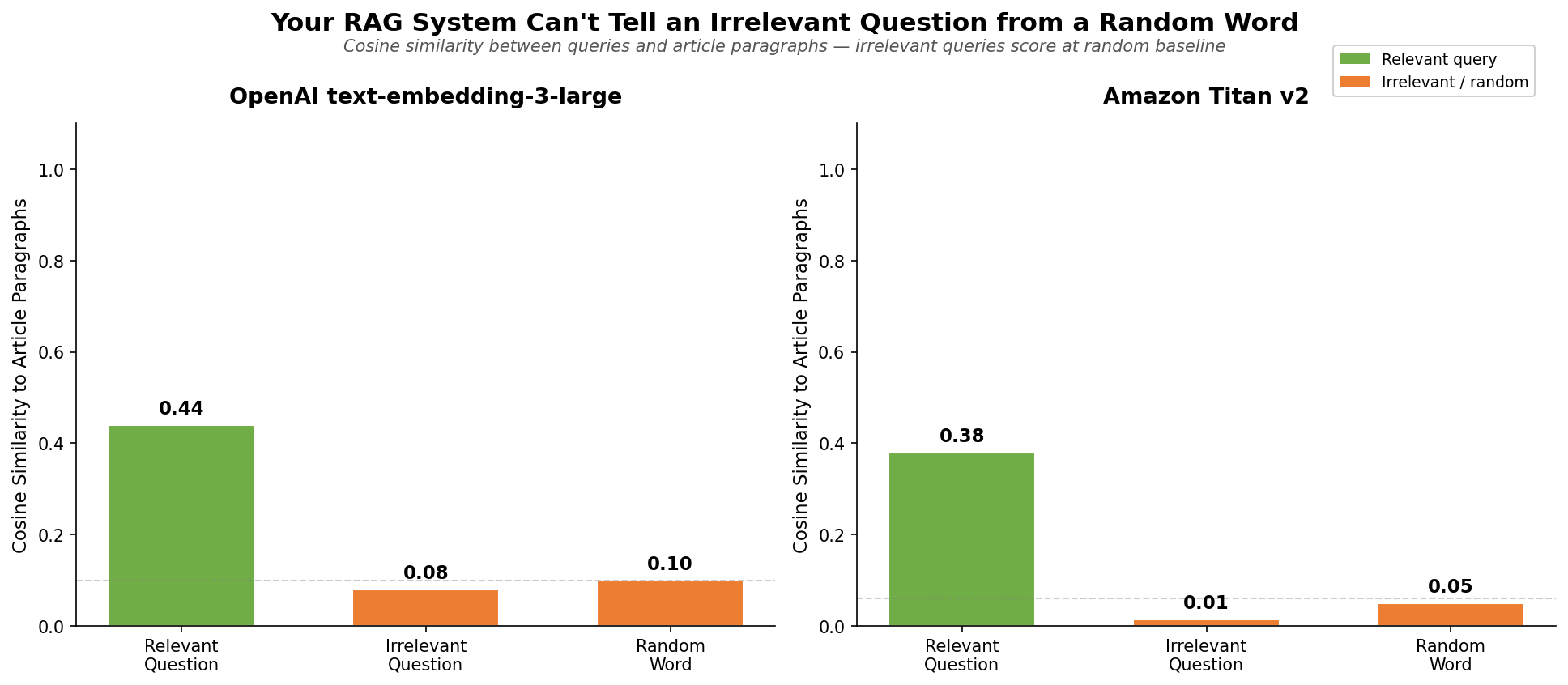
This is where it gets interesting. Here’s how queries compare to those chunk baselines:
| Input | OpenAI | Titan |
|---|---|---|
| Relevant question | 0.44 | 0.38 |
| Random word (from article) | 0.10 | 0.05 |
| Irrelevant question | 0.08 | 0.015 |
| Random English word | ~0.10 | ~0.05 |
A few things stand out:
A relevant question scores about the same as a random sentence from the article (0.44 vs 0.40 on OpenAI, 0.38 vs 0.32 on Titan). This makes intuitive sense - a question about fly fishing carries roughly as much topical signal as a random sentence from the article itself.
Whether a word appears in the article or not doesn’t matter. A random English word scores the same as a word pulled directly from the article (~0.10 on OpenAI, ~0.05 on Titan). At the single-word level, there’s no meaningful similarity signal - it’s all noise.
An irrelevant question scores worse than a random word (0.08 vs 0.10 on OpenAI, 0.015 vs 0.05 on Titan). A coherent sentence about the wrong topic gets actively pushed away from the article’s embedding, while a random word just floats at baseline. Being specifically off-topic is worse than being meaningless.
What This Means for RAG
Calibrate thresholds against your specific model. Both models agree on the hierarchy, but the absolute numbers differ. A threshold that works for OpenAI won’t transfer to Titan without re-measuring.
Test with irrelevant queries. Most people benchmark RAG only with queries they expect to match. The data shows that the gap between “relevant” and “noise” is where your threshold needs to live - and you can’t know where that is without measuring both sides.
Methodology
- Source text: Wikipedia article on fly fishing, truncated to 8,192 characters
- Chunk sampling: 10 random paragraphs, sentences, and words from the article, averaged across 5 runs
- Similarity metric: Cosine similarity via LlamaIndex
- Models: OpenAI text-embedding-3-large, Amazon amazon.titan-embed-text-v2:0
- Relevant questions: LLM-generated from the article content
- Irrelevant questions: Manually curated on unrelated topics
Comments